Chap06 | Synchoronization#
- Processes/threads can execute concurrently
- Concurrent access to shared data may result in data inconsistency
Race Condition#
Example
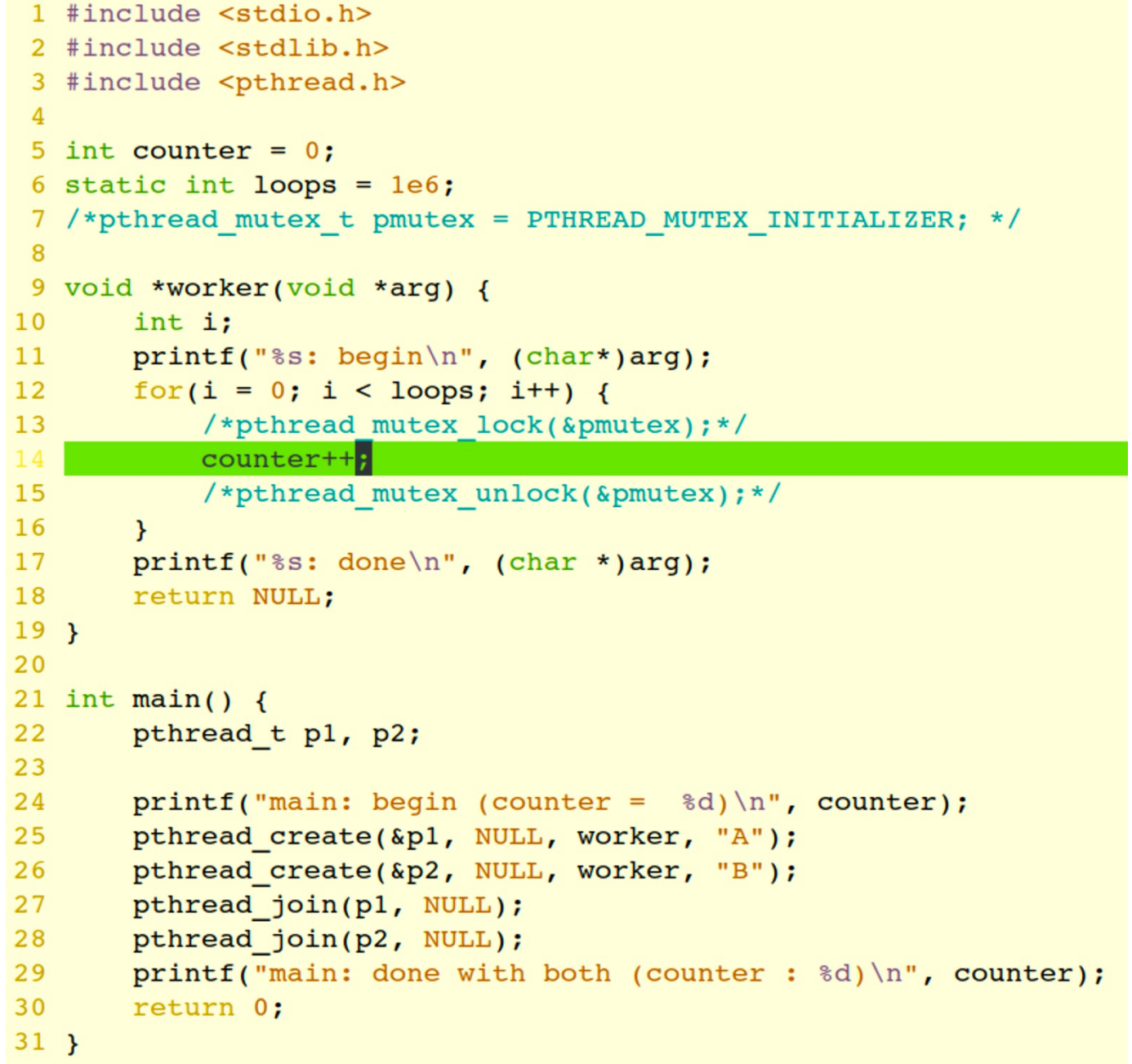

Several processes (or threads) access and manipulate the same data concurrently and the outcome of the execution depends on the particular order in which the access takes place, is called a race-condition.
多个进程并行地写数据,结果取决于写的先后顺序,这就是竞争条件。
在内核中,比如两个进程同时 fork,子进程可能拿到一样的 pid。
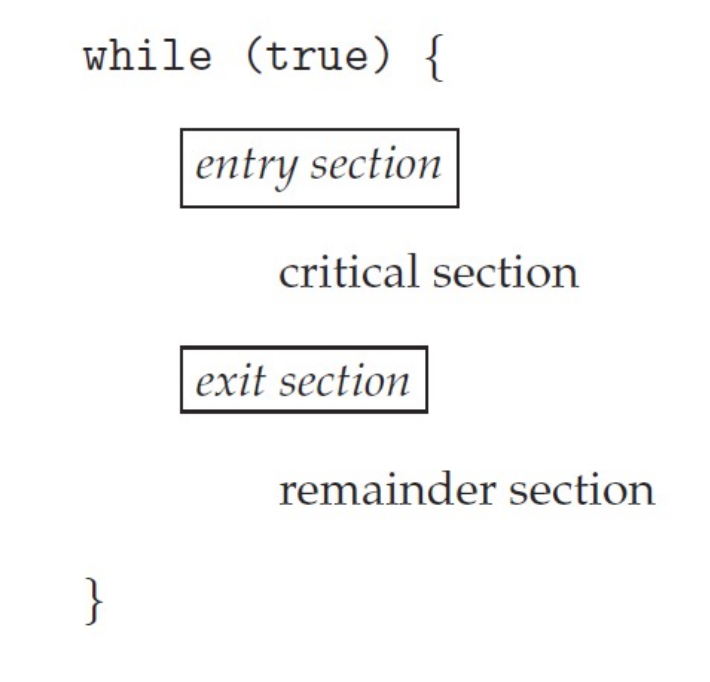
critical section#
修改共同变量的区域称为 critical section;共同区域之前叫 entry section,之后叫 exit section。
- Single-core system: preventing interrupts (关闭中断)
- Multiple-processor: preventing interrupts are not feasible (depending on if kernel is preemptive or non-preemptive)
- Preemptive – allows preemption of process when running in kernel mode
- Non-preemptive – runs until exits kernel mode, blocks, or voluntarily yields CPU
- 一定用synchronization来保护。
期末考点 三个条件
- Mutual Exclusion(互斥访问)
- 在同一时刻,最多只有一个线程可以执行临界区
- Progress(空闲让进)
- 当没有线程在执行临界区代码时,必须在申请进入临界区的线程中选择一个线程,允许其执行临界区代码,保证程序执行的进展
- Bounded waiting(有限等待)
- 当一个进程申请进入临界区后,必须在有限的时间内获得许可并进入临界区,不能无限等待
Peterson’s Solution#
Peterson’s solution solves two-processes/threads synchronization (Only works for two processes case)
- It assumes that LOAD and STORE are atomic
- atomic: execution cannot be interrupted
- Two processes share two variables
boolean flag[2]: whether a process is ready to enter the critical sectionint turn: whose turn it is to enter the critical section

验证三个条件(考试考点)
- Mutual exclusion
- P0 enters CS:
- Either
flag[1]=falseorturn=0 - Now prove P1 will not be able to enter CS
- Either
- Case 1:
flag[1]=false-> P1 is out CS - Case 2:
flag[1]=true,turn=1-> P0 is looping, contradicts with P0 is in CS - Case 3:
flag[1]=true,turn=0-> P1 is looping
- P0 enters CS:
-
Process requirement

-
Bounded waiting

Whether P0 enters CS depends on P1; Whether P1 enters CS depends on P0; P0 will enter CS after one limited entry P1
Peterson’s Solution is not guaranteed to work on modern architectures.
- Only works for two processes case
- It assumes that LOAD and STORE are atomic
-
Instruction reorder
指令会乱序执行。
Example

100 is the expected output.
但是线程 2 的代码可能被乱序,两条指令交换顺序,这样输出就可能变成 0。
Hardware Support for Synchronization#
Many systems provide hardware support for critical section code
- Uniprocessors: disable interrupts
- Solutions:
- Memory barriers
- Hardware instructions
- test-and-set: either test memory word and set value
- compare-and-swap: compare and swap contents of two memory words
- Atomic variables
Memory Barriers#
Memory model are the memory guarantees a computer architecture makes to application programs.
-
Strongly ordered – where a memory modification of one processor is immediately visible to all other processors.
一个内存的修改要立刻被所有的 processors 看到。
-
Weakly ordered – where a memory modification of one processor may not be immediately visible to all other processors.
A memory barrier is an instruction that forces any change in memory to be propagated (made visible) to all other processors.
Example

- X86 support
- 写内存屏障 (Store Memory Barrier):在指令后插入 Store Barrier,能让写入缓存中最新数据更新写入内存中,让其他线程可见。 强制写入内存,这种显式调用,不会让 CPU 去进行指令重排序。
- 读内存屏障 (Load Memory Barrier):在指令后插入 Load Barrier,可以让高速缓存中的数据失效,强制重新从内存中加载数据。也是不会让 CPU 去进行指令重排。
Hardware Instructions#
期末必考!!!
Special hardware instructions that allow us to either test-and modify the content of a word, or two swap the contents of two words atomically (uninterruptable)
Test-and-Set Instruction#
Defined as below, but atomically.
Lock with Test-and-Set
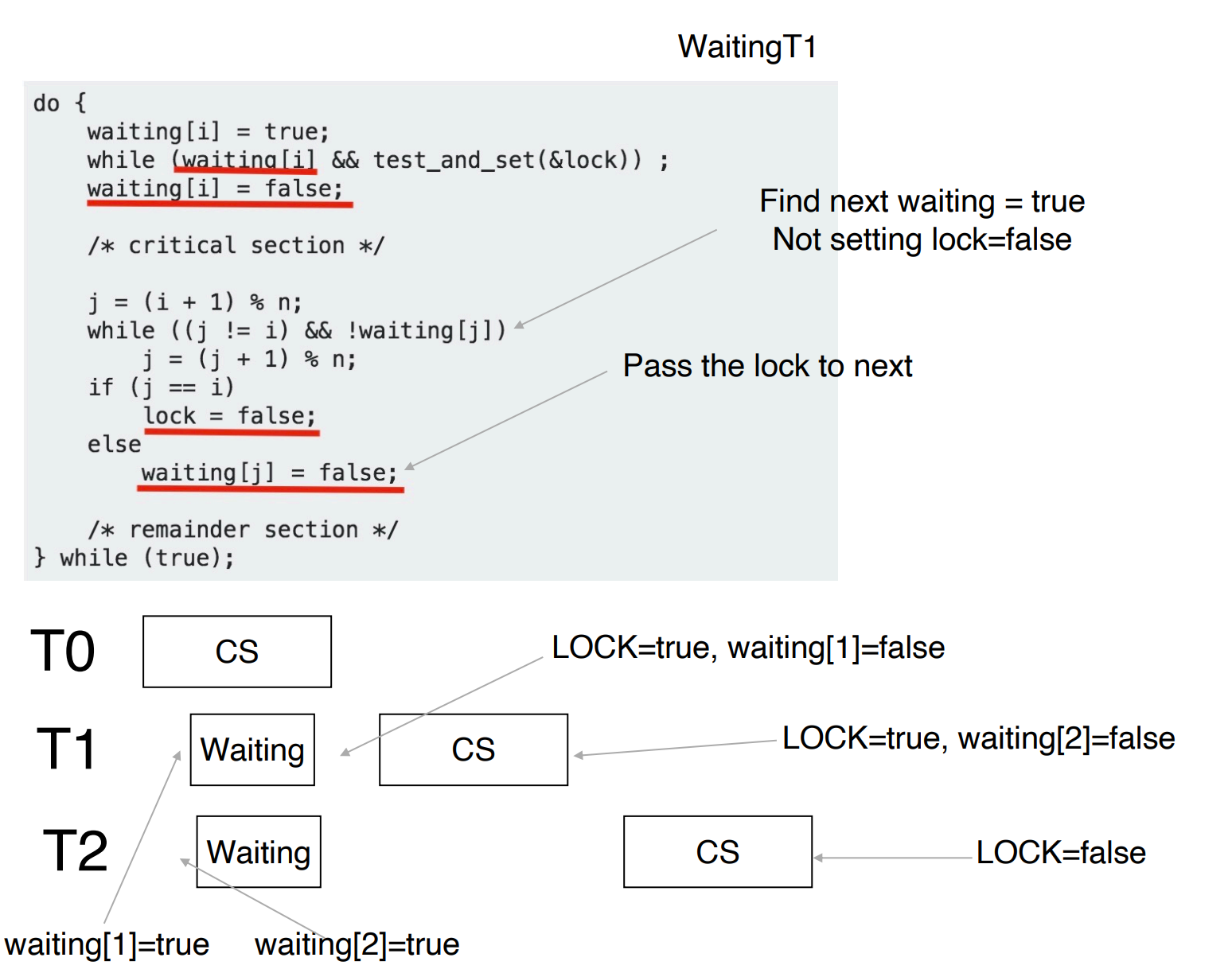
Bounded Waiting for Test-and-Set Lock
上面的程序满足前两个条件,不一定满足 bounded waiting。下面的代码可以把锁从 T0 传到 T1,再传到 T2。
Compare-and-Swap Instruction#
Executed atomically, the swap takes place only under this condition.
int compare_and_swap(int *value, int expected, int new_value)
{
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}
Shared integer lock initialized to 0;
while (true)
{
while (compare_and_swap(&lock, 0, 1) != 0); /* do nothing */
/* critical section */
lock = 0;
/* remainder section */
}
x86 中实现了 cmpxchg。
Atomic Variables#
One tool is an atomic variable that provides atomic (uninterruptible) updates on basic data types such as integers and booleans.
The increment() function can be implemented as follows:
void increment(atomic_int *v) {
int temp;
do {
temp = *v;
} while (temp != (compare_and_swap(v,temp,temp+1)));
}
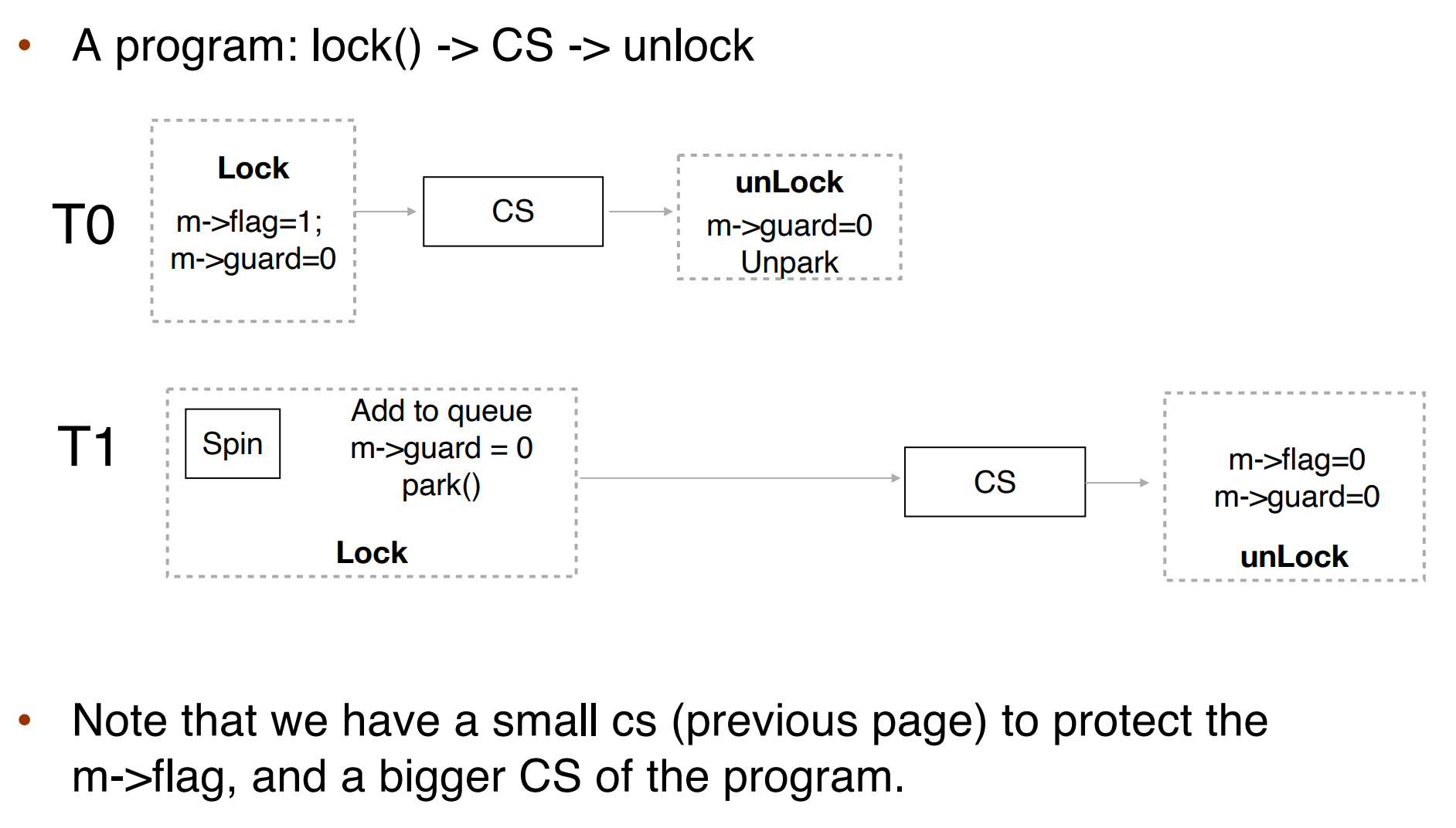
Mutex Lock#
Mutex Locks 支持 acquire() (获得这个锁)release()(释放这个锁)。因此 acquire, release 是原子的。
This solution requires busy waiting
- This lock therefore called a spinlock
bool locked = false;
acquire() {
while (compare_and_swap(&locked, false, true))
; //busy waiting
}
release() {
locked = false;
}
问题:如果一个进程有时间片,但是拿不到锁,一直 spin,会浪费 CPU 时间。
we put the busy waiting thread into suspended (yield-> moving from running to sleeping)
When the lock is locked, change process’s state to SLEEP, add to the queue, and call schedule()
Semaphore#
Synchronization tool that provides more sophisticated ways (than Mutex locks) for process to synchronize their activities.
Can only be accessed via two indivisible (atomic) operations
-
wait()andsignal()(Originally called P() and V() Dutch)-
wait()想拿到这个 semaphore,如果拿不到,就一直等待。
-
signal()释放 semaphore。
-
-
Counting semaphore – integer value can range over an unrestricted domain
- Binary semaphore – integer value can range only between 0 and 1
- Same as a mutex lock
Example
可以用来解决同步问题:

Semaphore w/ waiting queue#
要yield然后sleep,所以需要context switch
With each semaphore there is an associated waiting queue.
Two operations:
-
block– place the process invoking the operation on the appropriate waiting queue.把当前的进程 sleep,放到 waiting queue 里面。
-
wakeup– remove one of processes in the waiting queue and place it in the ready queue.从 waiting queue 里面拿出一个进程,放到 ready queue 里面。
Implemetation with waiting queue: (need to be atomic by spinlock)
wait(semaphore *S) {
S->value--;
if (S->value < 0) {
add this process to S->list;
block();
}
}
signal(semaphore *S) {
S->value++;
if (S->value <= 0) {
remove a proc.P from S->list;
wakeup(P);
}
}
这里有 busy waiting, 但在 critical section 里不需要(没有拿到 semaphor 就会 sleep,还没有走到 critical section),只有 wait 和 signal 里需要 busy wait。

Comparison between mutex and semaphore
- Mutex or spinlock
- Pros: no blocking
- Cons: Waste CPU on looping
- Good for short critical section
- Semaphore
- Pros: no looping
- Cons: context switch is time-consuming
- Good for long critical section
Semaphore w/ waiting queue in practice
真实实现里,需要有 spinlock 来保护 semaphore 操作的原子性。 21行和22行一定不能互换,否则会出现死锁。

Deadlock and Starvation#
-
Deadlock: two or more processes are waiting indefinitely for an event that can be caused by only one of the waiting processes.
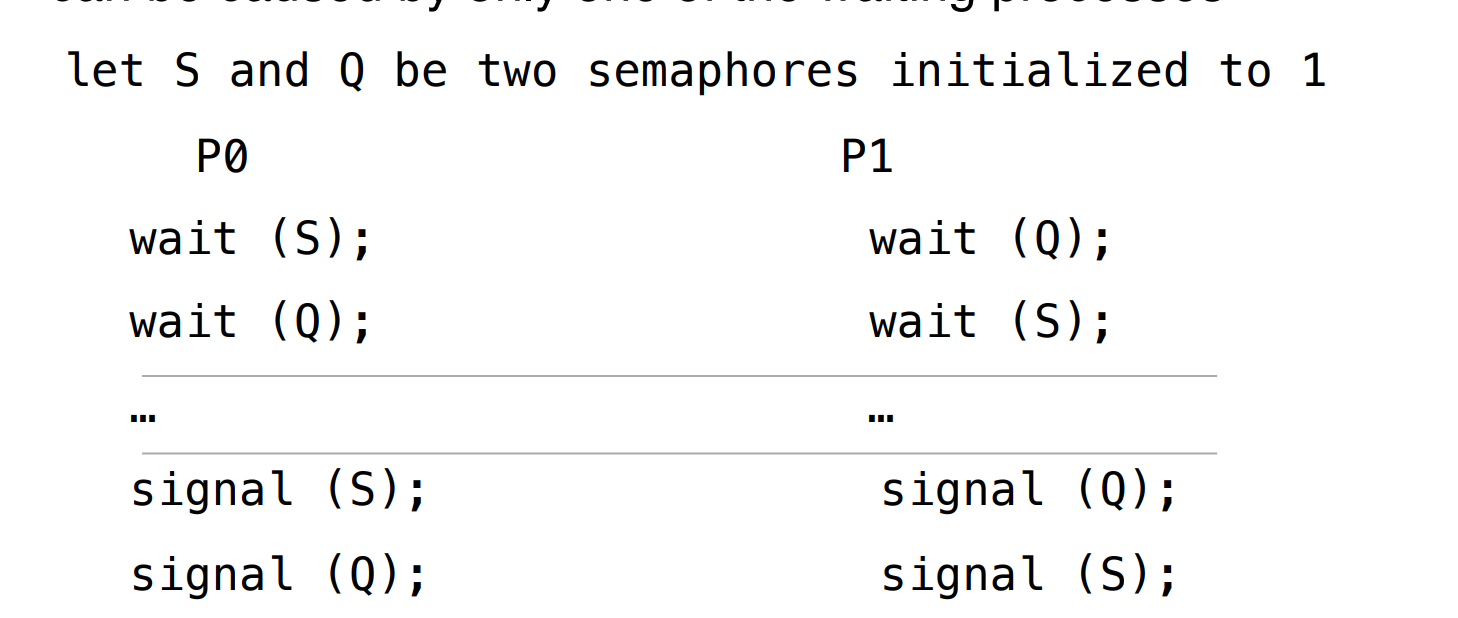
-
Starvation: indefinite blocking. a process may never be removed from the semaphore’s waiting queue.
Deadlock 是大家都拿不到锁,Starvation 是有的进程拿不到锁。
Priority Inversion#
Priority Inversion: a higher priority process is indirectly preempted by a lower priority task.
高优先级等低优先级(锁先被低优先级拿到),但是低优先级的进程拿不到 CPU,就无法释放锁。
Priority Inversion

Solution: priority inheritance
-
temporary assign the highest priority of waiting process (PH) to the process holding the lock (PL)
如果低优先级的进程拿到了锁,而且这个锁上有高优先级的进程在等,就提高低优先级的进程的优先级,继承锁的优先级(取决于在这个锁上等待的进程的最高的优先级)。
Linux Synchronization#
2.6 以前的版本的 kernel 中通过禁用中断来实现一些短的 critical section;2.6 及之后的版本的 kernel 是抢占式的。
Linux 提供:
- Atomic integers
- Spinlocks
-
Semaphores
在
linux/include/linux/semaphore.h中,down()是 lock(如果要进入 sleep,它会先释放锁再睡眠,唤醒之后会立刻重新获得锁),up()是 unlock。 * Reader-writer locks
POSIX Synchronization#
POSIX API provides
- mutex locks
- semaphores
- condition variable
Mutex Locks#
-
Creating and initializing the lock
-
Acquiring and releasing the lock
Semaphores#
Named semaphores can be used by unrelated processes, unnamed cannot.
sem_open(), sem_init(), sem_wait(), sem_post()
#include <stdio.h>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
#define NUM_THREADS 5
sem_t semaphore; // 定义信号量
void* access_resource(void* arg) {
int thread_id = *(int*)arg;
printf("Thread %d: Waiting to access resource...\n", thread_id);
// 等待信号量,尝试访问资源
sem_wait(&semaphore);
printf("Thread %d: Accessing resource...\n", thread_id);
sleep(1); // 模拟访问资源的操作
printf("Thread %d: Releasing resource...\n", thread_id);
// 释放信号量,表示离开资源
sem_post(&semaphore);
return NULL;
}
int main() {
pthread_t threads[NUM_THREADS];
int thread_ids[NUM_THREADS];
// 初始化信号量,设定初始值为3,表示最多允许3个线程同时访问资源
sem_init(&semaphore, 0, 3);
// 创建多个线程
for (int i = 0; i < NUM_THREADS; i++) {
thread_ids[i] = i + 1;
pthread_create(&threads[i], NULL, access_resource, &thread_ids[i]);
}
// 等待所有线程完成
for (int i = 0; i < NUM_THREADS; i++) {
pthread_join(threads[i], NULL);
}
// 销毁信号量
sem_destroy(&semaphore);
return 0;
}
Unamed Semaphores#
-
Creating an initializing the semaphore:
-
Acquiring and releasing the semaphore:
Named Semaphores#
-
Creating an initializing the semaphore:
-
Another process can access the semaphore by referring to its name SEM.
-
Acquiring and releasing the semaphore:
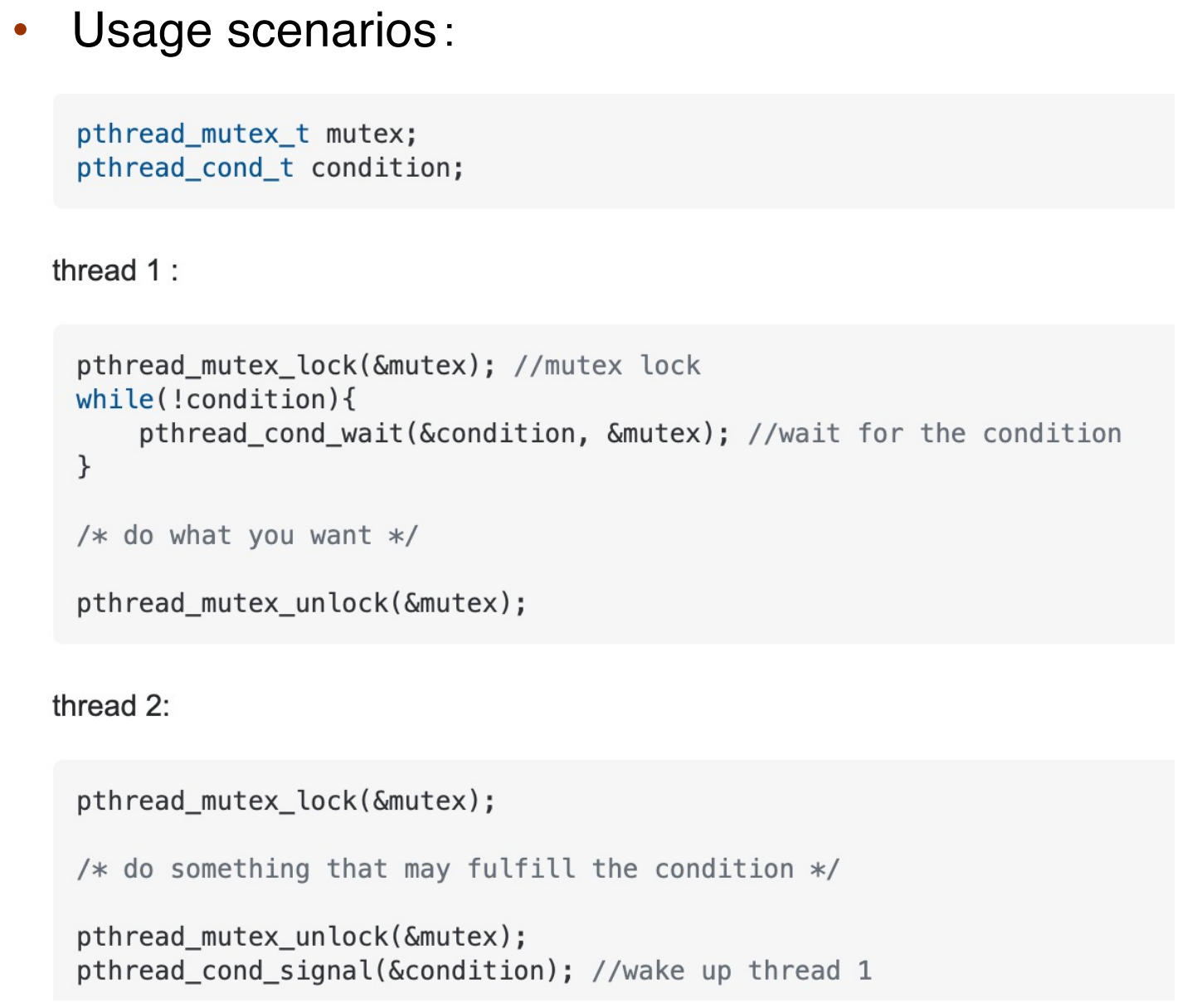
Condition Variable#
When should we use condition variables?

Operations supported by a condition variable are:
-
wait(condition, lock): release lock, put thread to sleep until condition is signaled; when thread wakes up again, re-acquire lock before returning.等待一个条件(先放锁然后睡眠,等待被唤醒,被唤醒之后重新获得锁)。
-
signal(condition, lock): if any threads are waiting on condition, wake up one of them. Caller must hold lock, which must be the same as the lock used in the wait call.唤醒一个等待线程。
-
broadcast(condition, lock): same as signal, except wake up all waiting threads.唤醒所有的等待线程。
pthread_mutex_t mutex;
pthread_cond_t cond_var;
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond_var, NULL);
// Thread waiting for the condition a == b to become true:
pthread_mutex_lock(&mutex);
while(a != b) // 一般要重复尝试,所以用 while 而不是 if
pthread_cond_wait(&cond_var, &mutex); // release lock when wait, acquire lock when being signaled
pthread_mutex_unlock(&mutex);
// Thread signaling another thread waiting on the condition variable:
pthread_mutex_lock(&mutex);
a = b;
pthread_cond_signal(&cond_var);
pthread_mutex_unlock(&mutex);
Example
- Condition variable can wake up all threads, semaphore can only wake up one by one.
-
Sometimes we only care if the queue is empty or not, while don’t care the queue length.
有的时候我们不关心等待队列的长度,那么 semaphore 的 val 就没有用处了。
-
Mutex is used to guarantee that operations are atomic.
Synchronization Examples#
每年必考一个大题,难度在1、2 之间
一般我们用信号量解决问题,因为信号量相对来说功能更多,而且很多操作系统对信号量做了更多设计,用来避免 busy waiting 等问题。
一个信号量用来表示 一类资源的余量;wait() 等待到其有余量时从中取走一个,而 signal() 释放一个资源。
Bounded-Buffer Problem#
Two processes, the producer and the consumer share n buffers
-
the producer generates data, puts it into the buffer.
-
the producer won’t try to add data into the buffer if it is full.
当 buffer 满的时候,生产者不能再放数据,应该 sleep。
-
-
the consumer consumes data by removing it from the buffer.
-
the consumer won’t try to remove data from an empty buffer.
当 buffer 空的时候,消费者不能再取数据,应该 sleep。
-
定义哪些 mutex 和 semaphor?
buffer 需要互斥的保护,因此需要一个 mutex。当它满了的时候就让 producer 睡眠,当它空的时候就让 consumer 睡眠,因此需要两个 semaphor。
- The producer process
这里
do { //produce an item ... wait(empty-slots); // 把 empty-slots 减一(初始为 N) wait(mutex); //add the item to the buffer ... signal(mutex); signal(full-slots); } while (TRUE)wait()的顺序不能调换:如果先wait(mutex),那么wait(empty-slots)之后,如果 buffer 空了,那么这个时候就会带着 mutex 休眠,这样另一个进程也拿不到这个锁了。 - The consumer process
Readers-writers problem#
A data set is shared among a number of concurrent processes
- readers: only read the data set; they do not perform any updates
- writers: can both read and write
多个 reader 可以共享,即同时读;但只能有一个 write 访问数据(写和读也不共享)。
Solution:
- semaphore mutex initialized to 1
- semaphore write initialized to 1
-
integer readcount initialized to 0
-
The writer process
- The reader process
mutex 用来保护
do { wait(mutex); readcount++; if (readcount == 1) wait(write); signal(mutex) //reading data ... wait(mutex); readcount--; if (readcount == 0) signal(write); signal(mutex); } while(TRUE);readcount。这里如果 count 是 1,就获得write的锁来保护这个 read。假设 writer 拿到了锁,来了 5 个 reader,那么第一个会 sleep 在 write 上,剩下 4 个 reader 会 sleep 在 mutex 上。
怎样才能不带着锁休眠?
Two variations of readers-writers problem
-
Reader first
如果有 reader holds data,writer 永远拿不到锁,要等所有的 reader 结束。
-
Writer first
如果 write ready 了,他就会尽可能早地进行写操作。如果有 reader hold data,那么需要等待 ready writer 结束后再读。
上面的代码是 Reader first。
write first
在 Readers-Writers 问题中,Write-First 策略优先考虑写者,确保一旦有写者请求写入,读者将被阻止,直到写操作完成。这样可以防止写者长时间等待,但可能导致读者延迟。
以下是 Write-First 策略的伪代码:
初始化变量
int read_count = 0 // 当前正在读的读者数量 boolean writer_waiting = false // 指示是否有写者等待 semaphore mutex = 1 // 保护读者计数器的锁 semaphore write_lock = 1 // 控制对资源的写入 semaphore read_lock = 1 // 控制对资源的读取(防止写优先时读者抢占资源)
写者(Writer)过程
writer() {
wait(mutex)
writer_waiting = true // 标记有写者等待
signal(mutex)
wait(write_lock) // 请求写入权限
// 进行写操作
write_data()
signal(write_lock) // 释放写入权限
wait(mutex)
writer_waiting = false // 清除写者等待标记
if (read_count > 0) // 若有读者等待,允许其读取
signal(read_lock)
signal(mutex)
}
读者(Reader)过程
reader() {
wait(mutex)
if (writer_waiting) // 若有写者等待,阻止读者进入
wait(read_lock) // 等待写者完成后才允许进入
read_count += 1
if (read_count == 1) // 第一个读者需要获得写入权限(防止写者打断读者)
wait(write_lock)
signal(mutex)
// 进行读操作
read_data()
wait(mutex)
read_count -= 1
if (read_count == 0) // 最后一个读者释放写入权限
signal(write_lock)
signal(mutex)
}
伪代码说明: 1. 写者优先:写者在请求时会设置 writer_waiting 标志,并请求 write_lock。在写者请求写入后,后续到来的读者在 read_lock 处等待,直到写者完成。 2. 读者控制: • 第一个读者进入时,会锁定 write_lock,防止写者在读者读完前抢占资源。 • 最后一个读者离开时释放 write_lock,允许写者进入。 3. 写者和读者等待释放:当写者完成后,若有读者等待且 read_count > 0,则通过 read_lock 允许读者进入。
Dining-philosophers problem#
Philosophers spend their lives thinking and eating, they sit in a round table, but don’t interact with each other.

每次只能拿一根筷子,但是要拿到两只筷子才能吃饭。例如如果每个人都先拿自己右边的筷子,再准备拿左边的筷子,就会卡死。
Solution: only odd philosophers start left-hand first, and even philosophers start right-hand first. This does not deadlock.
Takeaway#
Takeaway
- Data race
- Less than 2M example
- Reason
- Critical section
- Three requirements
- Peterson’s Solution
- Hardware Support for Synchronization
- Memory barrier, hardware instruction, atomic variables
- Mutex lock
- Semaphore
- Linux provides:
- atomic integers
- spinlocks
- semaphores
- reader-writer lock
Created: 2024年9月17日 14:52:21