CUDA入门基础#
导读
本站将记录CUDA语法的基础用法,以及一定的举例。具体问题的研究可以见其他板块。 [TOC]
1. 环境搭建#
其中编译时我们采用nvcc编译,用法类似gcc/g++。
如果只是编译多个源文件,即CUDA代码写到其他源文件里然后include到main文件时,需要添加编译选项
Attention: 有时候可能因为nvcc默认使用g++/gcc编译器不兼容,可以利用--compiler-bindir设定
2. CUDA 基础知识#
2.1 简单的代码结构以及示例#
作为开始,这里以一个简单的数组相加为例子,来介绍CUDA的代码结构,然后再逐个术语及语法做解释。在这之前,先预览CPU版的数组相加代码:
/*
CPU版代码
*/
void arrayAdd(float* dst, float* src1, float* src2, int n_data)
{
for (int i = 0; i < n_data; i++)
{
dst[i] = src1[i] + src2[i];
}
}
CUDA的整体代码比CPU代码冗长许多,但是真正参与计算的只有addKernel函数及其调用。一个简单且完整的CUDA代码分为:
设置参与运算的GPU cudaSetDevice 申请显存 cudaMalloc 复制数据 cudaMemcpy(参数cudaMemcpyHostToDevice) 调用kernel函数做运算 xxxKernel 等待运算结束后同步 cudaDeviceSynchronize(kernel函数的调用是异步的) 复制运算结果到到内存 cudaMemcpy (参数cudaMemcpyDeviceToHost) 释放显存 cudaFree
/*
CUDA版代码
*/
#include <iostream>
#include <cuda.h>
__global__ void addKernel(float *dst, float *src1, float *src2, int n_data)
{// kernel函数,具体计算实现
int i = threadIdx.x;
if (i < n_data) { dst[i] = src1[i] + src2[i]; }
}
bool arrayAddCuda(float* dst, float* src1, float* src2, int n_data)
{
cudaError_t cudaStatus = cudaSuccess;
// 设置运算GPU
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess)
{
std::cout << "Unable to set CUDA device " << cuda_dev_id << ", " << cudaGetErrorString(cudaStatus) <<"." << std::endl;
cudaDeviceReset();
return false;
}
// 申请显存
float *_d_src1 = nullptr;
float *_d_src2 = nullptr;
float *_d_dst = nullptr;
cudaStatus = cudaMalloc((void**)&_d_dst, n_data * sizeof(float));
if (cudaStatus != cudaSuccess)
{
std::cout << "Failed to allocate CUDA memory, " << cudaGetErrorString(cudaStatus) << "." << std::endl;
cudaDeviceReset();
return false;
}
cudaStatus = cudaMalloc((void**)&_d_src1, n_data * sizeof(float));
if (cudaStatus != cudaSuccess)
{
std::cout << "Failed to allocate CUDA memory, " << cudaGetErrorString(cudaStatus) << "." << std::endl;
cudaDeviceReset();
return false;
}
cudaStatus = cudaMalloc((void**)&_d_src2, n_data * sizeof(float));
if (cudaStatus != cudaSuccess)
{
std::cout << "Failed to allocate CUDA memory, " << cudaGetErrorString(cudaStatus) << "." << std::endl;
cudaDeviceReset();
return false;
}
// 把数据从内存复制到显存
cudaStatus = cudaMemcpy(_d_src1, src1, n_data * sizeof(float), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
std::cout << "Failed to copy memory from host to device, " << cudaGetErrorString(cudaStatus) << "." << std::endl;
cudaDeviceReset();
return false;
}
cudaStatus = cudaMemcpy(_d_src2, src2, n_data * sizeof(float), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
std::cout << "Failed to copy memory from host to device, " << cudaGetErrorString(cudaStatus) << "." << std::endl;
cudaDeviceReset();
return false;
}
// 调用kernel函数做运算
int block_dim = n_data;
int grid_dim = 1;
addKernel << <grid_dim, block_dim >> >(_d_dst, _d_src1, _d_src2, n_data);
// 等待GPU运算结束后同步
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess)
{
std::cout << "Failed to synchronized, " << cudaGetErrorString(cudaStatus) << "." << std::endl;
cudaDeviceReset();
return false;
}
// 把运算结果从显存复制到内存
cudaStatus = cudaMemcpy(dst, _d_dst, n_data * sizeof(float), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
std::cout << "Failed to copy memory from host to device, " << cudaGetErrorString(cudaStatus) << "." << std::endl;
cudaDeviceReset();
return false;
}
//释放显存
cudaFree(_d_src1);
cudaFree(_d_src2);
cudaFree(_d_dst);
cudaDeviceReset();
return true;
}
从上述例子可以发现,CUDA代码有两个部分。其中arrayAddCuda称为host code,既由CPU来执行。而addKernel为device code,一般都会以xxxkernel的方式命名,由GPU负责执行。除了括号里的数组作为参数,kernel函数的调用还带了三重尖括号<<<grid_dim, block_dim>>>。尖括号里边的两个参数声明了GPU里参与计算的线程数。而kernel函数里边就负责定义每个线程如何完成运算,每个线程通过线程ID threadIdx.x 来决定每个其所负责的数组的下标。
2.2 CUDA术语及语法#
2.2.1 CUDA线程分配(Thread,Block,Grid)#
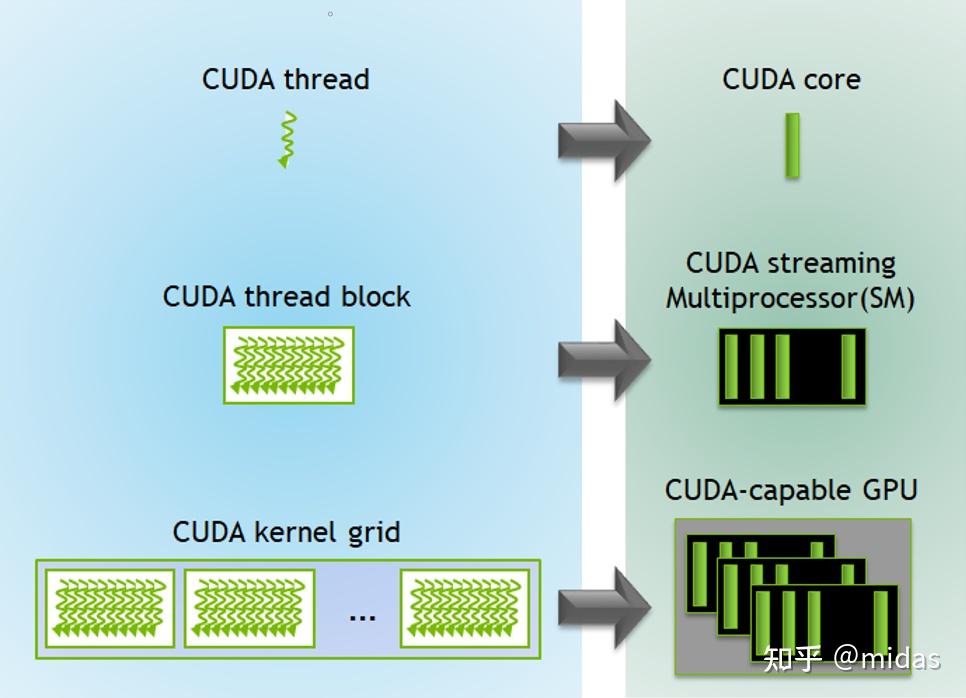
利用GPU做并行运算的核心是把任务派发到每个线程。我们需要根据任务来确定并行的线程数及任务分配细节。在此之前,我们需要理解CUDA里的Thread,Block和Grid这三个概念。这三个概念都是编程层面上的抽象,和硬件上的联系会在优化部分补充。
-
Thread——最小的运算单元,可以理解为CPU并行运算的线程。负责运行kernel函数里边所定义的运算。
-
Block——由多个Thread所组成的运算单元。每个block只能由GPU的单个由流处理器(Streaming Multiprocessor, SM)执行。单个Block最大支持1024个Thread。同一个Block的Thread可以通过共享内存(shared memory)沟通及交换数据。
-
Grid——由多个Block所组成,可以理解为一个GPU。一个Grid可以有最多655366553665536个Block。
上面三个概念可以简单概括为:整个Grid(GPU)由许多的Block组成,而Block里边又有许多的Thread,每个Thread都会执行我们所定义的kernel函数。kernel函数的调用是通过尖括号里的两个参数<<
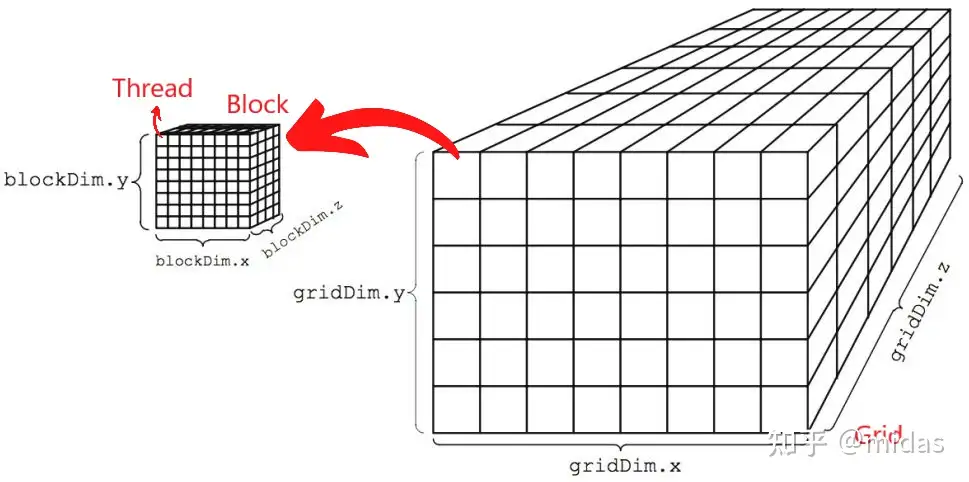
图源 http://harmanani.github.io/classes/csc447/Notes/Lecture15.pdf
但是实际应用中不一定需要用到六维,因此可以让其他维度的大小取为1,比如一维数组相加的例子。参数grid_dim和block_dim可以是CUDA定义的dim3结构,也可以是整数型int。
dim3 block_dim(5,4,3); // x=5, y=4, z=3
dim3 block_dim(5,4); // x=5, y=4, z=1
dim3 block_dim(5); // x=5, y=1, z=1
int block_dim = 5; // x=5, y=1, z=1
确定了需要调用的线程数后,接下来就是任务分配的细节。在kernel函数里,每个线程都有对应的threadIdx.x、threadIdx.y、threadIdx.z、blockIdx.x、blockIdx.y、blockIdx.z六个变量来唯一确定。同时Grid和Block的大小也可以通过blockDim.x、blockDim.y、blockDim.z、gridDim.x、gridDim.y、gridDim.z来获取。
一般情况下,我们很少用到6维度。以上述数组相加的例子,我们只用了一维的Block,即只有threadIdx.x是有意义的,并且用于对应数组中个别元素的位置。此外,这段代码还有一个问题。由于单个Block最多只能有1024个thread,当数组大于1024时会系统会报错。因此,我们需要增加一维的grid来处理大于1024的数组。为了使每个Thread单独对应到数组的每个元素,我们需要threadIdx.x、blockIdx.x及blockDim.x。

一维数组元素下标所对应的threadIdx.x和blockIdx.x。
__global__ void addKernel(float *dst, float *src1, float *src2, int n_data)
{// kernel函数,具体计算实现
int i = threadIdx.x + blockDim.x*blockIdx.x;
if (i < n_data) { dst[i] = src1[i] + src2[i]; }
}
bool arrayAddCuda(float* dst, float* src1, float* src2, int n_data)
{
...
// 调用kernel函数做运算
int max_block_dim = 1024;
int block_dim = max_block_dim ;
int grid_dim = n_data/1024 + (int)((n_data%max_block_dim )>0);
addKernel << <grid_dim, block_dim >> >(_d_dst, _d_src1, _d_src2, n_data);
...
}
如果是处理更高维的数据,并且需要映射到一维数组,可以参考:CUDA Indexing Cheatsheet
2.2.2 CUDA函数及变量修饰语法#
CUDA函数的修饰:
__global__声明kernel函数,由host(CPU)调用,device(GPU)执行。__device__声明device函数,由device调用,device执行。__host__声明host函数,由host调用,host执行。__device____host__由device调用,device执行;或者由host调用,host执行,主要用于测试和debug。
CUDA变量的修饰:
__device__声明变量,存在global memory。__shared__声明共享变量,存在shared memory,同一个bblock里的thread都可是有意义的,并且用于对应数组中个别元素的位置。此外,这段代码还有一个问题。由于单个block最多只能有1024个Thread,当数组大于1024时会系统会报错。因此,我们需要增加一维的Grid来处理大于1024的数组。为了使每个Thread单独对应到数组的每个元素,我们需要__constant__声明常量, 存在global memory。
2.3 CUDA线程的并行及同步#
当执行一个CUDA程序时,并非所有的thread都是同时并行的。理论上,同一个block里的所有thread是并行的。而不同block之间的并行取决于硬件的参数,即流处理器(SM)的数量决定。图10显示一段需要8个block的CUDA代码,是如何由两个不同GPU(2vs4流处理器)所执行的。左边的GPU只有2个流处理器,最多只能有2个block同时运行;而右边GPU有4个流处理器,最多能有4个block同时运行。
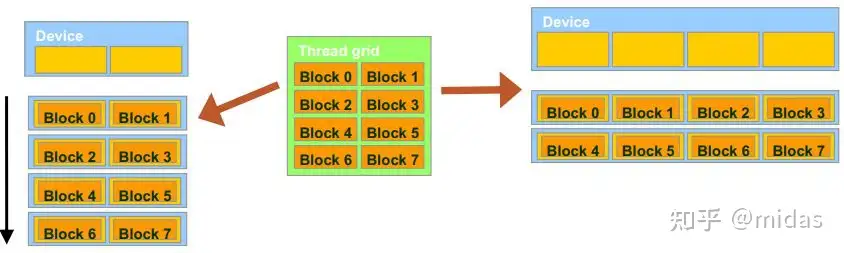
图源 http://harmanani.github.io/classes/csc447/Notes/Lecture15.pdf
只有同一个block里的thread才能同步。如果任务需要不同thread之间的协同,需要在kernel函数里对应位置加__syncthreads()。这里以一个图像的左右颠倒为例子。每个block负责一行,每个thread负责一个像素点。该thread负责读取对面像素点的值a,然后把自己像素点的值改成a。如果没有__syncthreads(),某个thread可能还来不及读取对面的值就被修改了,其结果如图所示。
__global__ void flipHorizontalKernel(float* src_dst, int nx, int ny)
{
int i = blockIdx.x;
int j = threadIdx.x;
int loc1 = i*nx + j;
int loc2 = i*nx + (nx - 1 - j);
float tmp = src_dst[loc2];
__syncthreads();
src_dst[loc1] = tmp;
}
bool flipHorizontalCuda(float* src_dst, int nx, int ny)
{
...
int block_dim = nx;
int grid_dim = ny;
// 调用kernel函数做运算
flipHorizontalKernel << <grid_dim, block_dim >> >(_d_src_dst, nx, ny)
...
}

3. 优化#
3.1 架构优化#
3.2 并行优化#
3.3 访存优化#
3.4 CUDA stream#
Created: 2023年12月7日 19:50:16